
参照此文章编写https://rocky.github.io/blackhat-asia-2024-additional/all-notes-print
Python 字节码的变化非常大,每个版本之间都有很大的区别。高级字节码的一个方面:许多源信息(如变量名称及其类型)都保存在字节码中。所以反编译回来的程序会和源代码非常像(简直一模一样)。但是来自源文本的注释不会显示在重建结果中,这是因为这些注释不会出现在字节码中的任何位置。
The disassembler is great with code that doesn’t have jumps in it. But once we have jumps, like we have in the highlighted instructions, a disassembler has to stop combining instructions.
反汇编器非常适合没有跳转的代码。但是,一旦我们有了跳转,就像我们在突出显示的指令中一样,反汇编器必须停止组合指令。
With each new Python release, control flow decompilation has become increasingly more difficult. Nowadays, about 1/3 of the issues raised in the decompiler bug trackers are related to control flow.
随着每个新的 Python 版本的发布,控制流反编译变得越来越困难。如今,反编译器错误跟踪器中提出的问题中约有 1/3 与控制流有关。
Grammars and the grammar-based approach we use, however, can naturally parse nesting and sequencing control structures quite well. So having a methodical way to characterize control flow that fits into the decompiler parsing can give more precision and accuracy that is not available in general-purpose decompilers
然而,语法和我们使用的基于语法的方法可以很自然地很好地解析嵌套和排序控制结构。因此,有一种有条不紊的方法来表征适合反编译器解析的控制流,可以提供通用反编译器所不具备的更高的精度和准确性
There are other decompilers for Python. They all start out with a disassembly, even the one I looked at that uses machine learning. Many build a tree—more or less—based on instructions from a disasssembly, and they all produce source text from that internal tree-ish structure.
Python 还有其他反编译器。它们都是从拆解开始的,即使是我看到的那个使用机器学习的拆解。许多人或多或少地根据反汇编的指令构建了一棵树,并且它们都从内部的树状结构中生成源文本。
However, they are a bit more ad hoc. None use the grammar-based approach here. The phases are fewer and a little less distinct.
但是,它们更具临时性。这里没有使用基于语法的方法。相位较少,也不太明显。
General-purpose decompilers like you find in Ghidra are largely different. They live in a more complicated world. To be able to do things across a wider spectrum of machine languages and a wider spectrum of programming-language environments, they largely give up on the hope of noticing specific patterns of instructions. This came up in the chained-comparison example. The ability to match specific patterns is what makes these decompilers produce extremely intuitive and accurate results and written in the programming language that the source text was also written in.
像你在 Ghidra 中发现的通用反编译器有很大不同。他们生活在一个更加复杂的世界里。为了能够在更广泛的机器语言和更广泛的编程语言环境中做事,他们在很大程度上放弃了注意到特定指令模式的希望。这出现在链式比较示例中。匹配特定模式的能力使这些反编译器能够产生极其直观和准确的结果,并且是用编写源文本的编程语言编写的。
Control Flow, in General-purpose decompilers, is its own canned phase. This phase doesn’t take into account the specific target programming language that produced the code and the specific set of control-flow structures that the source language has.
在通用反编译器中,控制流是它自己的固定阶段。此阶段不考虑生成代码的特定目标编程语言以及源语言具有的特定控制流结构集。
Our control flow is intimately tied to the control flow for a particular Python version. When Python added a new construct like “async” co-routines in Python 3.5, it added a new kind of control-flow pattern match. Python has an extremely rich set of control-flow structures. I know of no canned control-flow-detection mechanism that would be able to cover all control-flow mechanisms that Python includes like the “else” clauses on “while”, “for”, and “try” blocks.
我们的控制流与特定 Python 版本的控制流密切相关。当 Python 在 Python 3.5 中添加类似“异步”协程的新构造时,它添加了一种新的控制流模式匹配。Python 具有一组极其丰富的控制流结构。据我所知,没有一种预制的控制流检测机制能够涵盖 Python 包含的所有控制流机制,例如“while”、“for”和“try”块上的“else”子句。
Our approach uses tokenization to facilitated parsing. This is similar to the lift phase that general-purpose decompilers often do after initial disassembly . In general-purpose decompilers, the lifting language is sometimes to LLVM or an LLVM-like language. In Python, our intermediate language is very much tied to Python bytecode. In general, that is true for all high-level bytecode decompilers. The intermediate code looks like the high-level bytecode. Also, this intermediate language drifts over time along with the language and bytecode drift.
我们的方法使用标记化来促进解析。这类似于通用反编译器在初始反汇编后经常执行的提升阶段。在通用反编译器中,提升语言有时是 LLVM 或类似 LLVM 的语言。在 Python 中,我们的中间语言与 Python 字节码密切相关。通常,所有高级字节码反编译器都是如此。中间代码类似于高级字节码。此外,这种中间语言会随着语言和字节码的漂移而漂移。
作者给出了实验性的新代码,Chained Compare Parse Tree 链式比较解析树
python开发
python打包成exe的方法https://saucer-man.com/information_security/825.html
编写了个小代码来进行下面的逆向
pyinstaller -F -w -n active exercise.py
1 | -F 或 --onefile:这个选项告诉 PyInstaller 将所有文件打包进一个单独的可执行文件中。这样做的好处是分发和运行应用程序更为简单,因为所有依赖项都包含在这个单一文件中。 |
.45hmk0kgkd.webp)
(太容易报毒了建议暂时关掉防护,把我刚生成的exe文件删掉了)
解包exe
Pyinstxtractor
Pyinstxtractor可以解包exe
1 | https://sourceforge.net/projects/pyinstallerextractor/ |
执行后就像这样

一般来说我们会获得一个和我们解包的exe同名的pyc文件,这个时候就和第一种类型题目一样,将pyc文件还原成py文件进行逆向即可。
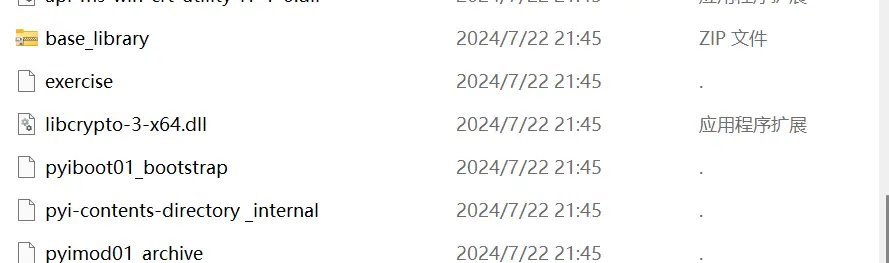
解包文件后文件组成
PYZ-00.pyz_extracted非常重要,一般一个稍微大一点的项目都会分成多个py文件,甚至会依赖其他模块,这些被依赖的文件解析后都会放入PYZ-00.pyz_extracted中,可以说这里放的是核心代码。
pyc逆向
pyc结构
pyc文件分为pyc文件头部分和PyCodeObject部分。文件头部分即为上文中谈到的魔数时间戳部分,而PyCodeObject是在CPython(Python 的官方解释器实现)中用来表示编译后的代码对象的结构体。实际上,pyc 文件就是 PyCodeObject 对象在硬盘上的保存形式。
不同版本的python的魔数头
PyObject_HEAD
不同的 Python 版本会有不同的 PyObject_HEAD:
| Python 版本 | 十六进制文件头 |
| Python 2.7 | 03f30d0a00000000 |
| Python 3.0 | 3b0c0d0a00000000 |
| Python 3.1 | 4f0c0d0a00000000 |
| Python 3.2 | 6c0c0d0a00000000 |
| Python 3.3 | 9e0c0d0a0000000000000000 |
| Python 3.4 | ee0c0d0a0000000000000000 |
| Python 3.5 | 170d0d0a0000000000000000 |
| Python 3.6 | 330d0d0a0000000000000000 |
| Python 3.7 | 420d0d0a000000000000000000000000 |
| Python 3.8 | 55 0d 0d 0a 00 00 00 00 00 00 00 00 00 00 00 00 |
| Python 3.9 | 610d0d0a000000000000000000000000 |
| Python 3.10 | 6f0d0d0a000000000000000000000000 |
| Python 3.11 | a70d0d0a000000000000000000000000 |
PyCodeObject 的结构如下:
1 | typedef struct { |
代码->pyc字节码
字节码文件的扩展名通常以“.pyc”结尾,或“.pyo”
1.compileall
1 | python -m compileall test.py |
成功编译后会当前目录生成相应文件夹和文件
1 | V PYTHONEX |
现在我用的是3.8.18,所以用decompyle3和uncompyle6分别试试反编译
结果
1 | PS D: anquan_reandpwn \pythonex\pyctest> decompyle3 exercise. cpython-38.pyc |
对于这些参数的解释
1 | 以 # 开头是注释。顶部的部分包含一些元数据,这些元数据存储在字节码文件中。它不是我们之前在十六进制中看到的 25 字节指令序列的一部分(不是代码执行的一部分) |
我没下载相对应的uncomply6版本,就不演示了
2.dis库(disassember ):
There is a disassember in the standard Python Library called dis. Most novice decompilers use this— it’s the first thing that comes to mind. But that has some serious limitations. The biggest limitation is that it can only disassemble code for a single Python version, the version that is runining the decompiler. If you are running the latest version of Python, such 3.12, but the bytecode you want to analyze is from an earlier version, like bytecode from 2.7, then you are out of luck. Malware written in Python tends to use older versions of Python. This was the situation when Microsoft folks contacted me.
在标准 Python 库中有一个名为 disassember 的dis。大多数新手反编译器都使用它——这是首先想到的。但这有一些严重的局限性。最大的限制是它只能反汇编单个 Python 版本的代码,即运行反编译器的版本。如果您运行的是最新版本的 Python,例如 3.12,但要分析的字节码来自早期版本,例如 2.7 的字节码,那么您就不走运了。用 Python 编写的恶意软件倾向于使用旧版本的 Python。当Microsoft的人联系我时,情况就是这样
显示字节码的方法
1 | import dis |
pyc字节码->代码
uncompyle6的详细介绍
1 | pip install uncompyle6 |
uncompyle6的工作原理:
Get bytecode disassembly using xdis. xdis is the cross-version disassembly library that I wrote to be able to support these decompilers. It is also useful in other projects that work with Python bytecode.
使用 xdis 获取字节码反汇编。xdis 是我(uncompyle6作者,这段文字复制于原文)编写的跨版本反汇编库,以便能够支持这些反编译器。它在使用 Python 字节码的其他项目中也很有用。“ Tokenize” the disassembly. “Tokenize” is a compiler-centric term. In other decompilers and code-analysis tools, this process is sometimes called lifting, as in “lifting the disassembly” or “lifting the machine code”.
“标记化”反汇编。“Tokenize”是一个以编译器为中心的术语。在其他反编译器和代码分析工具中,此过程有时称为提升,如“提升反汇编”或“提升机器代码”。Parse tokens to create a Parse Tree.
解析令牌以创建解析树。Abstract the parse tree to an “Abstract Syntax Tree”, and finally:
将解析树抽象为“抽象语法树”,最后:Produce Python source text from the Abstract Syntax Tree.
从抽象语法树生成 Python 源文本。
在机器代码中,操作数通常是寄存器值,可以是数字、地址或地址的一部分。在 Python 字节码中,操作数是任意的 Python 对象!
xdis
https://pypi.org/project/xdis/
uncompyle6 和 decompile3 使用 xdis——“跨 Python 反汇编器”。
1 | pip install xdis |
结果如下(如果你看了前面的文章链接,就会发现我这里生成的数据和作者的不一样,也许是版本原因,我使用的是python3.8.18,xdis使用的是6.1.1):
1 | $pydisasm -F extended-bytes -S exercise.cpython-38.pyc |
pycdc
1 | https://github.com/extremecoders-re/decompyle-builds |
decompyle3
它只处理 Python 3.7 和 3.8。
1 | pip install decompyle3 |
加花的pyc
Python 字节码控制流分析
Python control_flow
python序列化和反序列化
marshal(读写pyc字节码):
marshal 模块是 Python 内置的一个模块,用于在二进制格式和 Python 对象之间进行序列化和反序列化。与 pickle 模块不同,marshal 模块主要用于处理 Python 字节码,并且不保证跨 Python 版本的兼容性。通常,marshal 用于读写 .pyc 文件中的字节码。
marshal 模块的常用函数
**
marshal.dump**:将 Python 对象序列化到文件中。**
marshal.load**:从文件中反序列化 Python 对象。**
marshal.dumps**:将 Python 对象序列化为二进制数据。**
marshal.loads**:将二进制数据反序列化为 Python 对象
利用示范
对象和文件
1 | import marshal |
对象和二进制数据
1 | import marshal |